Just like with numpy arrays, the range provided is inclusive of the first value, but not the second value. You can also select data from pandas dataframes without knowing the location of that data within the pandas dataframe, using specific labels such as a column name. In addition to location-based and label-based indexing, you can also select data from pandas dataframes by selecting entire columns using the column names. Pandas.DataFrame.loc function can access rows and columns by its labels/names.

It is straight forward in returning the rows matching the given boolean condition passed as a label. Notice the square brackets next to df.loc in the snippet. From the above example, we have data about luxury brands called "lux". We want to print the name and prices of these brands using Pandas indexing in Python Dataframe. Later, we define the dataframe as df and access the data of the luxury brands and add the index values of the products, which are represented by p_1,p_2,p_3,p_4. Thus, the system numbers these index values starting from 0 and identify the rows and the columns and finally prints out the output.

In the data frame, we are generating random numbers with the help of random functions. Here the index is given with label names of small alphabet and column names given with capital alphabets. The index contains six alphabet means we want rows and three columns, also mentioned in the 'randn' function. In the above small program, the .iloc gives the integer index and we can access the values of row and column by index values. To know the particular rows and columns we do slicing and the index is integer based so we use .iloc.

The first line is to want the output of the first four rows and the second line is to find the output of two to three rows and column indexing of B and C. The keys of the dictionary are the DataFrame's column labels, and the dictionary values are the data values in the corresponding DataFrame columns. The values can be contained in a tuple, list, one-dimensional NumPy array, Pandas Series object, or one of several other data types.

You can also provide a single value that will be copied along the entire column. A data frame is a method for storing data in rectangular grids for easy overview. If you have knowledge of java development and R basics, then you must be aware of the data frames. The measurements or values of an instant corresponds to the rows in the grid whereas the vectors containing data for a specific variable represent the column.

Hence, the rows in the data frame can include values like numeric, character, logical and so on. Similar is the data frame in Python, which is labeled as two-dimensional data structures having different types of columns. The Python Pandas data frame consists of the main three principal components, namely the data, index and the columns.

We can also use the colon range operator to get a contiguous set of rows or columns by position. Note that unlike the .loc[] function using labels, the .iloc[] function using positions does not include the endpoint. In this case, it returns only columns zero and one, and does not return column two. Selecting single or multiple rows using .loc index selections with pandas.

Note that the first example returns a series, and the second returns a DataFrame. You can achieve a single-column DataFrame by passing a single-element list to the .loc operation. Pandas index is also termed as pandas dataframe indexing, where the data structure is two-dimensional, meaning the data is arranged in rows and columns. We generated a data frame in pandas and the values in the index are integer based.

Here we checked the boolean value that the rows are repeated or not. For every first time of the new object, the boolean becomes False and if it repeats after then, it becomes True that this object is repeated. Creating a data frame in rows and columns with integer-based index and label based column names. As an alternative to selecting rows and columns by their labels, we can also select them by their row and column number.

The ordering of the columns, and thus their positions, depends on how the data frame is initialized. The index column, our 'name' column, doesn't get counted. There are a lot of ways to pull the elements, rows, and columns from a DataFrame. (If you're feeling brave some time, check out Ted Petrou's 7(!)-part series on pandas indexing.) Some indexing methods appear very similar but behave very differently. The goal of this post is identify a single strategy for pulling data from a DataFrame that is straightforward to interpret and produces reliable results. Just a warning - these are my own thoughts only and they come with no guarantees of being authoritative or even accurate.
In this Pandas tutorial we are creating a list of colors and using that list we create a pandas series. Pandas series objects have immense use in single column data like time series data and custom indexing makes data wrangling much easier. The necessity to find the indices of the rows is important in feature engineering. These skills can be useful to remove the outliers or abnormal values in a Dataframe.

The indices, also known as the row labels, can be found in Pandas using several functions. In the following examples, we will be working on the dataframe created using the following snippet. You can use it to get entire rows or columns, or their parts.

After working with indexing for Python lists and numpy arrays, you are familiar with location-based indexing. There is some indexing method in Pandas which helps in selecting data from a DataFrame. The .loc and .iloc indexers use the indexing operator to make selections.
We don't have to limit ourselves to a single row or single column using this method. That's why in this case, the index is called multi-index. Note that .iloc returns a Pandas Series when one row is selected, and a Pandas DataFrame when multiple rows are selected, or if any column in full is selected. To counter this, pass a single-valued list if you require DataFrame output. There are multiple ways to select and index rows and columns from Pandas DataFrames.

The dataframe.index returns the row label of the dataframe as an object. The individual property is to be accessed by using a loop. You can use it to get entire rows or columns, as well as their parts. Pandas in Python makes it extremely easy to work and play with data analysis concepts. Having the option to gaze upward and use works quick permits us to accomplish a specific stream when composing code.
Pandas DataFrame rows and columns traits are useful when we need to process just explicit rows or columns. It is additionally valuable to get the mark data and print it for future investigating purposes. In the above program, we add the same rows and columns in multiple lines and finally invoke the set index function, which thus gives the output. Pandas.reset_index in pandas is used to reset index of the dataframe object to default indexing or to reset multi level index.

By doing so, the original index gets converted to a column. The Python and NumPy indexing operators [] and attribute operator '.' provide quick and easy access to pandas data structures across a wide range of use cases. The index is like an address, that's how any data point across the data frame or series can be accessed. There are several ways to do this, but the most common is by using the Pandas iloc method. The Pandas iloc method enables you to retrieve rows and columns by the integer location. Pandas set_index() is a library method used to set the list, Series, or dataframe as an index of the dataframe.

It takes keys, drop, append, inplace, andverify_integrityas parameters and returns the data frame with index using one or more existing columns. We can select specific ranges of our data in both the row and column directions using either label or integer-based indexing. We have created a function that accepts a dataframe object and a value as argument. It returns a list of index positions ( i.e. row,column) of all occurrences of the given value in the dataframe i.e.

You've just inserted another column with the score of the Django test. The parameter loc determines the location, or the zero-based index, of the new column in the Pandas DataFrame. Column sets the label of the new column, and value specifies the data values to insert.
As you can see, .dtypes returns a Series object with the column names as labels and the corresponding data types as values. In most cases, you'll use the DataFrame constructor and provide the data, labels, and other information. You can pass the data as a two-dimensional list, tuple, or NumPy array.

You can also pass it as a dictionary or Pandas Series instance, or as one of several other data types not covered in this tutorial. In addition to using indexing, you can also select or filter data from pandas dataframes by querying for values that met a certain criteria. Pandas provide various methods to get purely integer based indexing. We used the loc method to select a single row by the index value. In this particular case, we had set the name variable as the "index" for the sales_data DataFrame.

That means that the individual names (like 'William', 'Sofia', 'Markus', etc) have become the index values that identify each row. In addition, we can select rows or columns where the value meets a certain condition. In this case, we want to find the rows where the values of the 'summitted' column are greater than 1954. In the rows position, we can put any Boolean expression that has the same number of values as we have rows. In this method, we can set the index of the Pandas DataFrame object using the pd.Series(), and set_index() function.

First, we will create a Python list and pass it to the pd.Series() function which returns a Pandas series that can be used as the DataFrame index object. Then we pass the returned Pandas series to the set_index() function to set it as the new index of the DataFrame. In this tutorial we will learn how to get the index or position of substring in a column of a dataframe in python – pandas. There are several ways that you can create the Pandas DataFrame.

In most cases, you will use the DataFrame constructor and fill out the data, labels, and other information. Sometimes, you will import the data from a CSV or Excel file. Then, you can pass the data as the two-dimensional list, tuple, or NumPy array.

You can also give it the dictionary or Pandas Series instance or one of many other data types not covered in this example. With a slight change of syntax, you can actually update your DataFrame in the same statement as you select and filter using .loc indexer. This particular pattern allows you to update values in columns depending on different conditions. The setting operation does not make a copy of the data frame, but edits the original data.
Now in the bool dataframe iterate over each of the selected columns and for each column find rows which contains True. Now these combinations of column names and row indexes where True exists are the index positions of 81 in the dataframe i.e. A random selection of rows or columns from a Series or DataFrame with the sample() method. The method will sample rows by default, and accepts a specific number of rows/columns to return, or a fraction of rows. Provide quick and easy access to pandas data structures across a wide range of use cases.

This makes interactive work intuitive, as there's little new to learn if you already know how to deal with Python dictionaries and NumPy arrays. However, since the type of the data to be accessed isn't known in advance, directly using standard operators has some optimization limits. For production code, we recommended that you take advantage of the optimized pandas data access methods exposed in this chapter. In Python Pandas.index.get_loc method return integer location and this method works with sorted and unsorted indexes. It will check the condition if the value is not present then it will return the next value to the passed value only if the index values are sorted. Now let's take an example and solve this problem by iterating the column names.

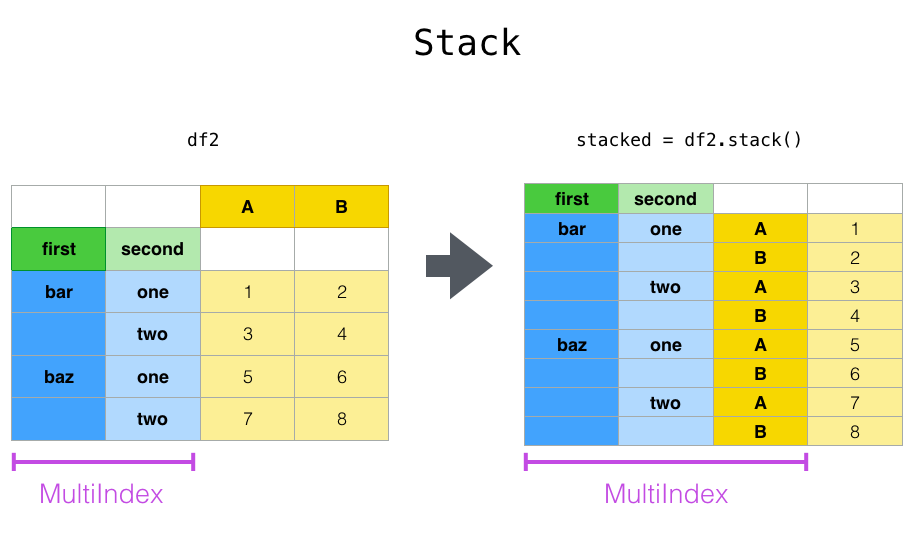
To do this task first we have created a DataFrame object 'df' in which we have assigned a specific column name 'Numbers'. Once you will print 'df' then the output will show the 'Numbers' value index of a DataFrame. In this table, the first row contains the column labels (name, city, age, and py-score). Multiple Indexes or multiline indexes are nothing but the tabulation of rows and columns in multiple lines.

Pandas Index is a permanent array executing an orchestrated, sliceable set. It is the fundamental thing that stores the center names for all pandas objects. It returns an array which substitutes the index object of the array.
If needed, review how to create matplotlib plots with lists, and then substitute the list names with series selected from the pandas dataframe. Which provides the data from the column as a pandas series, which is a one-dimensional array. A pandas series is useful for selecting columns for plotting using matplotlib. Object selection has had several user-requested additions to support more explicit location-based indexing. Pandas now support three types of multi-axis indexing for selecting data.



